
This is the second installment in our series — if you feel lost, check out our first article and work your way up towards this one.
Most people imagine a SPAM Filter to be a single piece of software — a black box that receives emails, applies all kinds of secret logic rules, then spits out a single label of “spam” or “not spam”. And they think this way for a reason… deliverability vendors LOVE to perpetuate this view because it spreads fear and helps them sell deliverability products/consulting services.
However, our multi-year research has found this to be largely untrue. Yes, spam filters have a lot of moving parts and complex interactions, but they tend to be very mechanical and easy to understand. And once you know HOW they work, it becomes easy to work with the spam filters to optimize deliverability instead of against them with gimmicky cat-and-mouse features (eg: multi-domain inbox rotation).
In this article, we’ll help you understand how spam filters work, so that in our next article, we can use this knowledge to evaluate the most common deliverability tactics that exist in the market today (as well as some better ones that are lesser known 😀)
The Spam Filter pipeline
Spam filters are not a single piece of software — rather, they are a pipeline of various software that works together to produce a result of blocking undesired emails.
Understanding this pipeline is key for two reasons. First, because it lets us address the deliverability problem in smaller, more manageable chunks. Second, because it gives us valuable clues into the inherent constraints that spam filter operators have, which we can take advantage of.
What are these contraints?
The first constraint is expertise. As you’ll see below, effective spam filtering requires expert knowledge of networking, operating system, software and AI/ML. Because no single vendor can ever master all of these areas, the spam filter has to operate these filtering mechanisms as individual modules, which means that each module will inherently only look at certain parts of the email being received at one time.
The second constraint is cost. Some 90% of all email traffic today is SPAM, which makes operating these types of systems extremely expensive. Taking a pipeline approach allows these filters to mitigate cost in a big way. For example, looking up an IP blocklist on a local firewall is extremely cheap/fast vs. analyzing an email with AI, so we know that SPAM filters will frontload that type of check. We also know that emails blocked in the networking stack are never even seeing by software running on the operating system, so when debugging certain types of deliverability issues, we can very easily know that we don’t need to throw away an entire domain/inbox/IP and start from scratch.
With this pipeline model in mind, let’s look at the various components below.
Layer 1: Network Layer
Firewall
The networking/firewall stack on a server is already optimized to filter requests based on IP-based rules. It’s incredibly resource efficient and the go-to method for managing IP based blocks.
For larger scale systems, there will be a firewall that sits in front of many email servers, and for smaller systems, each server will run its own firewall and they may not always be synchronized (or there may be some delay).
These systems are also always unique to each ESP, meaning getting caught in one won’t impact deliverability everywhere). Also, getting caught in these filters usually has a ‘half-life’, meaning you will become unbanned depending on the frequency/severity of your activity. These explain part of the volatility in behavior we can see when it comes to deliverability to a given ESP.
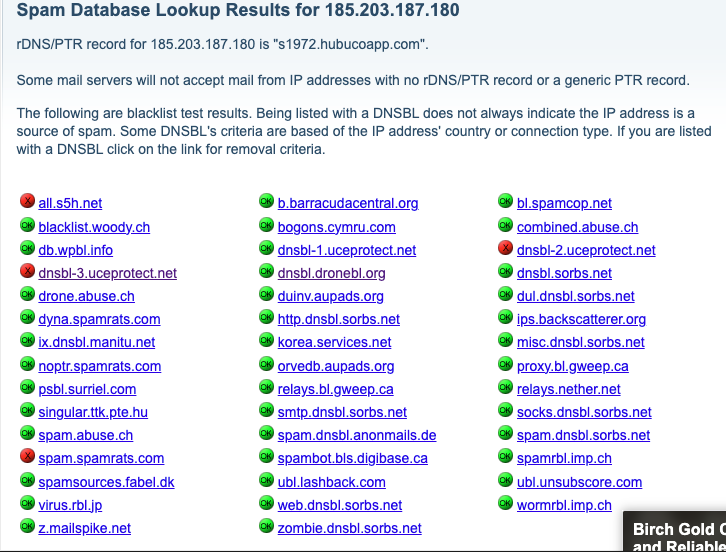
Distributed Realtime Blocklists
Realtime Blocklists (RBLs) are decentralized databases that blacklist specific ips/domains based on complaints. Any email server can query these databases in an extremely cost efficient way using DNS lookups.
The problem with these blacklists is that anyone can submit a complaint (either automatically from their server, or manually) and there is very limited oversight into whether these claims are even legitimate. As a result, you could send a hundred thousand emails without issues but that one stringent/difficult lead having a bad day can get you blacklisted, thereby blocking you from delivering to the next hundred thousand leads.
This is one of the main factors that can make deliverability seem very random/arbitrary, which is another source of the fear that email marketers experience around deliverability
Whois Lookups
Whois databases give us easy access to information about domains — specifically the registrar and age of the domain. These are fast, easy and free to do.
While we haven’t done explicit research into this area, we found very clearly that we would regularly get listed across RBLs when trying to send from a domain less than one month old, which is usually why senders who follow the ‘you got blocked? spin up new domains!’ advice end up in a downward spiral of deliverability issues.
Geofiltering
If you are a German ad agency who only works with German clients, the odds are low that you’ll get emails from other countries, even lower that you’ll get email from other continents, and even lower from certain countries known for generating a high volume of SPAM.
Geofiltering traffic allows admins to change behavior based on the relevance of the sender’s geography. And while this may seem like a very arbitrary heuristic, we’ve seen many cases where switching geolocation solved spam filtering for clients, so it is something we suggest not overlooking when planning deliverability (using servers in proximity to your target clients).
This is another dimension that explains the variability one may observe in deliverability.
Infrastructure Lookups
We can infer a lot about the content of an email based on the characteristics of the infrastructure that sent it. For example, emails that come from Gmail/Outlook implicitly go through some scrutiny, in that these services both do a lot of proactive email blocking and customer vetting. Also, emails that come from legitimate providers that make it difficult to get access to Port 25 (AWS, Azure, GCP) are a positive signal whereas using companies that make this port freely available (vultr, OVH cloud, etc) is a negative signal.
These lookups are extremely cheap and yet another dimension that we’ve seen impact deliverability.
SIDENOTE: in the open source Spamassassin filter, the default weighting for a trusted sender is (-3) points, which often can single handedly take your score from a very clear ‘spam’ number to being borderline legitimate. We believe this is one of the biggest reasons why sending from Gmail/Outlook did so well, for so long, when even amateur senders were doing mass email. This is clearly not the case today.
Log Analysis Tools
Almost all email systems employ log analysis tools to detect unusual patterns and take action based on them (ex: Fail2Ban, Datadog, etc)
The idea works like this:
You come up with a series of signals and the volume of those signals to label as a ‘red flag’. For example, “failed login attempts, 100 times over 60s from a single IP” might be indicative of a brute force attacker trying to randomly guess passwords at high frequency.
The log analysis software runs in the background and rolls up the log data over fixed windows to try to find matching rules. If one is found, the IP in question gets banned.
A new/improved approach to this involves “anomaly detection”, where logs are analyzed continuously by machine learning algorithms to detect large deviations in activity (this is one of the reasons ramping up email volume is a recommended best practice — to avoid these anomaly detection algorithms).
This mechanism can often help explain why you can get away with high activity at first from a brand new domain and it can take a full day before you start seeing your first deliverability issues. It also explains why behavior can seem so different across ESPs and different enterprise email servers, since these rules are always highly customizable and easy to customize.
Layer 2: Email Header & Content
DNS Records
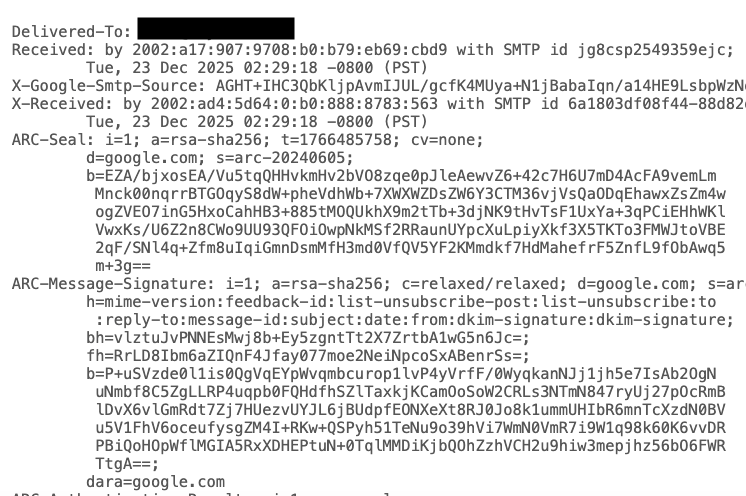
At this point, DNS/DKIM/DMARC are the bare minimum any sender needs to have any hope of getting delivery (never mind getting to the primary inbox). The published standards keep increasing across vendors, so this will be familiar to you all.
What may be less familiar is the importance of reverse DNS — this is a mapping that allows you to confirm that a given IP does indeed belong to the domain/host that is included in the email content. While this sounds simple, it puts a constraint on a popular in-house email sending architecture of tying multiple domains/IP addresses to a single server, which is what many high volume sending experts do.
Distributed Content Check
Far cheaper than analyzing the raw email content is identifying if the same email has been “mass blasted” at high volume across the internet.
A content checker software like Pyzor takes an email, intelligently strips it down (eg: remove attachments, remove email signatures, etc) and generates a single string of characters (a “hash”) that can easily be indexed, counted and queried at scale. Advanced content checkers
This behavior explains some common cold email wisdoms*:
Not adding email signatures: email signatures are really easy to detect, never change (unlike email copy) and are often the same across many different sending accounts, making them ideal for detecting a single person sending many emails across many inboxes/domains.
Adding Spintax: although most content checkers have no problems detecting/accounting for spintax, this is the mechanism that this feature tries to evade.
This mechanism can also explain why so many different configurations of sending can lead to many different results in terms of deliverability — for example, high quality cold email senders swearing that saying that “email signatures don’t matter” while others swear the opposite.
* Note: we give these as examples and not as endorsements, in future articles we’ll explore just how effective these wisdoms actually are.
Declarative Content Checks
There are many hardcoded rules that spam check software have built up over the years to detect spam.
Spam Keywords/Topics: “totally free!”, “offer only valid today”, “bitcoin”
Email Structure: hidden img pixels used for email tracking, having a high ratio of images to text, having no text in the email body, having an email be less than 100 chars, etc.
These are rules that have been built up in most filters based on decades of fighting various SCAM campaigns and when diving deep into these, it becomes very easy to see legitimate cold email traffic can be confused with SPAM (for example, promising to save a prospect “millions of dollars” with your SaaS vs. promising to “make them millions of dollars” through a scam.
These rules are very different based on the software being used (eg: Barracuda vs. Spamassassin) which can further explain the volatility that we see in deliverability results.
AI/ML Based Content Checks
The final content check involves letting ML/AI models look at the entire message and try to generate a prediction score of whether or not a given email is SPAM. This will likely generate multiple scores, taking into account the user’s past inbox activity, the activity across different email tenants, etc.
This layer produces multiple layers of variability when it comes to inbox placement testing, because of the customization at the user level around spam/inbox rules (for example, I’ve reported so much spam that Gmail hasn’t shown me an SDR email in over two years). As a result, this requires very careful planning.
Layer 3: Human Feedback
SPAM Reports
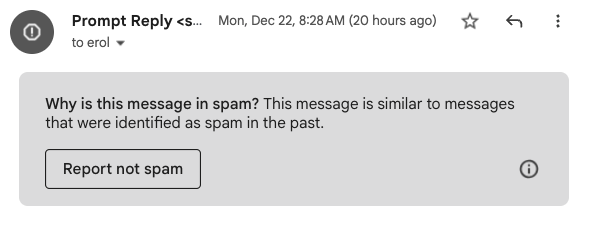
There is no bigger impact on how your emails are delivered than someone hitting the ‘SPAM’ report. For email recipients, this is a fairly big deal to do because it’s implying they never want to hear from this sender again, which is not typical for anyone who has any type of real relationship with the sender (eg: if I have an account at Chase bank and they send me an email from a wealth manager that I don’t like, I would never report that as spam in case I miss a legitimate email from my vendor.).
Getting reported as spam is a nuclear event to be avoided at all costs. Unfortunately, similar to the RBLs, this reporting applies in a distributed way across all email recipients, although it seems to have a relative weighting based on the recipient (this is inconclusive at this point, we plan to research this in a future study).
Contact Lists
Adding a sender to a contact list puts the sender in a permanent whitelist at a user level. This happens when the user adds a contact or replies to an email from the sender once.
This makes testing for deliverability especially difficult — once an email is tested against one inbox for delivery/placement, it can never truly be tested the same way against that same inbox/domain, adding more to the volatile experience senders have with email deliverability.
How To Manage The Complexity
If you’ve made it this far in the article, you may feel overwhelmed.
There are so many components to this.
Many components interact with each other, meaning there are lots of permutations to think about.
This gets even more complex in a distributed system (eg: gmail has different email servers running in different data centers)
This gets even more complex when you realize different ESPs share information (eg: blacklists)
You may be wondering “how on earth do I build a system that accounts for all of this?” Or “when something goes wrong, where the heck do I even start debugging the problem?”
We felt this way too, but fortunately, when you pull all of these pieces together, it turns out that there are only a handful of optimal architectures for cold email sending that can work well.
In our next article, we’ll talk through three architectures/approaches you can use to execute outbound with reasonably high confidence, and the many associated tradeoffs. Don’t want to miss the article? Subscribe to our blog below!

Michael Schwanz
Author